


Qwen in Practice
In the last post, we set up Qwen-3.6 and connected it to Claude Code, allowing us to host our own LLM instead of relying on paid API tokens. It was time to find out whether it could actually be used for practical work. Having a local chatbot was nice enough, but we wanted to add some additional capabilities so that our self-hosted setup would move a bit closer to the experience offered by commercial AI platforms. The first feature we decided to tackle was local image generation directly from chat.
The basic problem is that VRAM is limited. In our case, we have 32GB available on the RTX 5090, and Qwen-3.6, which powers our OpenWebUI setup, already fills most of it. A serious image generation model running through ComfyUI — in our case Flux.2 — also consumes a large amount of VRAM, so there is no realistic way to run both at the same time on the GPU.
We could try heavily offloading parts of the models to system RAM, where we have 128GB available, but that comes with a significant performance penalty. The models would still run, just much more slowly, which largely defeats the purpose of having powerful local hardware in the first place.
The Orchestrator
The solution we found is using an orchestrator middleware that sits between OpenWebUI and the image generation stack. It exposes an image generation API to OpenWebUI, but instead of trying to keep everything running simultaneously, it dynamically switches between the language model and the image generation model depending on what is needed at the time.
When an image generation request arrives, the orchestrator performs the following sequence:
Stop the llama.cpp container hosting Qwen-3.6
Start ComfyUI with the image generation configuration
Submit the image generation request and wait for the result
Shut down ComfyUI
Restart llama.cpp
Return the generated image to OpenWebUI
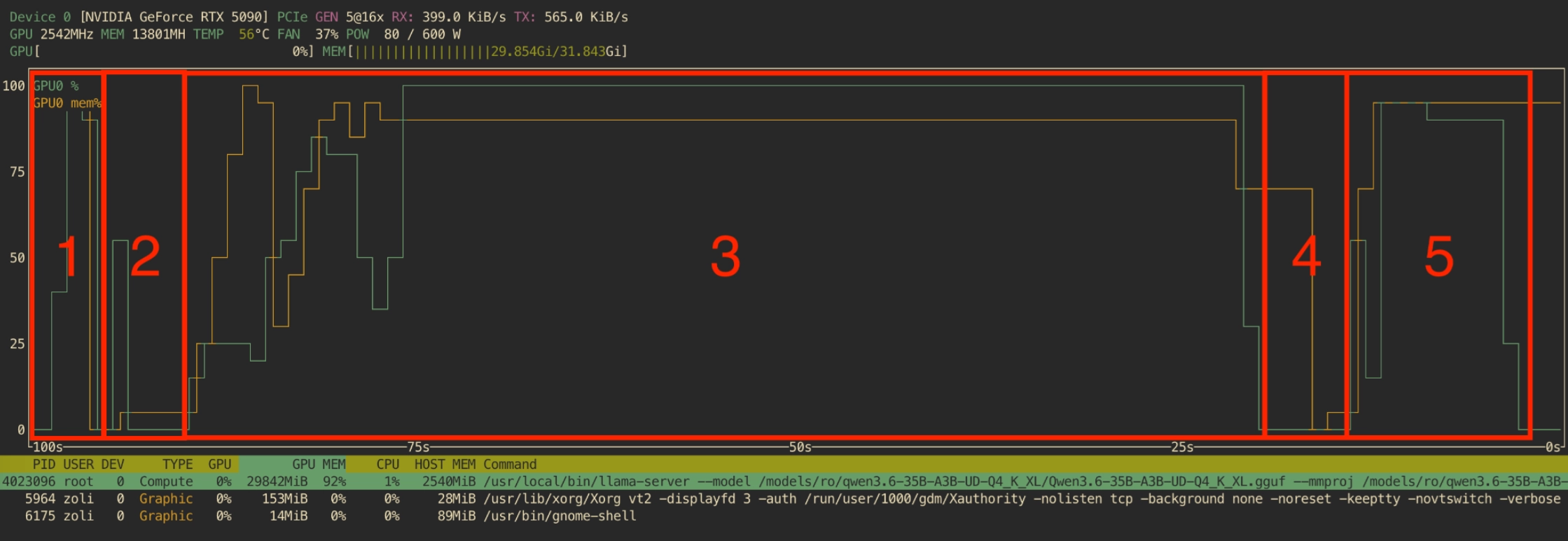
This allows both OpenWebUI and ComfyUI to make full use of the GPU while they are running, instead of competing for the same limited pool of VRAM. OpenWebUI does not even need to be aware that the underlying model has been stopped and restarted while the image is being generated. It simply issues an image generation request and waits for the result. It does not need to know that the underlying language model has been shut down and restarted while the tool call is being processed.
Of course, there is some overhead associated with stopping and starting models, but it is still much better than running them heavily offloaded to system RAM. Once the new model is loaded into memory, it can use the entire GPU at maximum efficiency.
Look Ma, No Brains!
One particularly interesting observation during development was that Claude Code itself was using the local Qwen-3.6 instance running through the very same llama.cpp container that the orchestrator needed to shut down during testing. As a result, it happened quite a few times that Claude Code initiated an end-to-end test, the orchestrator stopped llama.cpp as part of the workflow, and then brought it back online once the image generation cycle had completed.
This meant that Claude Code was effectively performing brain surgery on itself while believing it was simply testing an orchestrator completely unrelated to its own operation.
Most of the time it did not seem to notice at all. In some cases it attempted to start additional sub-agents while llama.cpp was offline, entered a retry loop for a short period, and then continued normally once the model became available again. Despite repeatedly losing access to the very LLM powering it, Claude Code was generally able to recover gracefully and continue its work without any intervention.
Benchmark results
We tested image generation using the orchestrator flow at the following resolutions:
Resolution | Sides Scale | Pixel Multiplier | Megapixels |
1024×768 | 1x | 1x | 0.79 MP |
1536×1152 | 1.5x | 2.25x | 1.77 MP |
2048×1536 | 2x | 4x | 3.15 MP |
2560×1920 | 2.5x | 6.25x | 4.92 MP |
3072×2304 | 3x | 9x | 7.08 MP |
3584×2688 | 3.5x | 12.25x | 9.63 MP |
4096×3072 | 4x | 16x | 12.58 MP |
Pure image generation time scales linearly up to around 2560×1920, below that it’s even a bit sublinear, above that it clearly becomes superlinear, likely as the computation turns from compute-bound to memory bandwidth-bound at around this scale.
The actual swap overhead is almost constant while the resolution changes, so at higher scales it becomes less and less significant. Here are the absolute values:
And here the relative values, where we see the ratio of swap overhead to actual useful image generation work. The initial 26% seems relatively large, but it converges to around 2.8% as we increase the resolution.
Even though 26% overhead at the lowest resolution seems relatively large, we still get an image delivered in less than a minute straight into the chat interface, and knowing all the things that are happening in the background to make that happen makes this not just acceptable, but also kind of cool.
Final Thoughts
Of course, we would be lying if we said that relatively small local LLMs are superior to serious cloud-based models. Quite the opposite. Having Opus 4.8 behind Claude Code is an entirely different weight class. You have to explain things fewer times, it makes fewer mistakes, and you can generally trust it to make better decisions. Local models require a little patience. You have to explain things repeatedly, correct them more often, and occasionally guide them back onto the right track. But in the end, Qwen was able to fight its way through the problem. It implemented the orchestrator, added fallback paths for failure scenarios, and generally managed to get the system into a state where it could recover gracefully if something went wrong.
More importantly, there is a certain freedom in owning the entire stack. You can burn through thousands of prompts, run questionable experiments, get stuck down obscure rabbit holes, and generally waste tokens with complete abandon. The marginal cost is low enough that you never have to think about it. Whether or not the setup is objectively cheaper than commercial alternatives, it certainly feels different when every interaction is no longer tied to an API bill.